8. Python for Fundamental Analysis: Unlock Insights with Earnings Call Transcript Analysis
Welcome back to the Python for Fundamental Analysis series! We’ve built a strong quantitative toolkit over the last posts:
- Calculating P/E Ratio
- Automating Financial Statement Retrieval
- Calculating & Visualizing Profitability Ratios
- Analyzing Liquidity Ratios (Current & Quick)
- Analyzing Debt Ratios (Debt-to-Equity)
- Measuring Operational Efficiency (Turnover Ratios)
- Automate Peer Company Analysis & Benchmarking
While numbers are essential, they don’t capture management strategy, competitive dynamics, outlook, or the nuances behind performance. For this, we turn to qualitative sources, and one of the richest is the earnings call transcript. These quarterly calls offer direct commentary from management and revealing Q&A sessions with analysts.
In this post, we’ll use Python and the FMP API to fetch earnings call transcripts. We’ll then explore two ways Python can help us navigate this dense text: first, through basic keyword frequency analysis, and second, by attempting to identify sentences potentially relevant to specific questions we might have about the company’s performance or outlook.
Understanding Earnings Call Transcripts
What Are They?
Post-earnings release calls where management presents results and outlook, followed by analyst Q&A. Transcripts are the written record.
Why Are They Important for Analysis?
- Management Tone & Strategy: Direct insights into priorities, plans, and confidence levels.
- Risk Disclosure: Discussion of potential headwinds and challenges.
- Analyst Concerns: Questions highlight key investment community focus areas.
- Context for Numbers: Management’s narrative explaining why the quantitative results look the way they do.
Challenges
Transcripts are long and unstructured. Python can help us navigate them more efficiently.
Python Implementation: Fetching Transcripts & Basic Analysis
Let’s write the code. We’ll fetch a specific transcript, count keyword frequencies, and attempt to find sentences related to predefined questions.
API Key & Libraries: Use your FMP API key (replace placeholder or use environment variables). Ensure pandas(optional), requests, matplotlib, and Python’s built-in re (regular expressions) library are available (pip install pandas requests matplotlib).
import requests
import pandas as pd # Optional, mainly if you want to store metadata
import matplotlib.pyplot as plt
import os
import re # Import regular expression module for sentence splitting
# --- Configuration ---
# API Key provided by user (Normally, use environment variables for security)
API_KEY = "your api key"
# Base URL for FMP API version 3
BASE_URL = "https://financialmodelingprep.com/api/v3"
# --- Parameters for Transcript ---
TICKER = "AAPL"
YEAR = 2025
QUARTER = "Q1" # Options: Q1, Q2, Q3, Q4
# Keywords to search for in the transcript (for frequency analysis)
KEYWORDS_TO_SEARCH = [
"growth", "risk", "challenge", "opportunity", "ai", "artificial intelligence",
"margin", "guidance", "outlook", "competition", "innovation",
"supply chain", "inflation", "interest rate", "debt", "cash flow", "vision pro"
]
# --- NEW: Questions to find potential answers for ---
# Define questions relevant to the company and period
QUESTIONS_TO_ANALYZE = [
"What is the outlook for iPhone sales growth?",
"How are supply chain challenges impacting margins?",
"What are the plans for future AI integration?",
"What was mentioned about Vision Pro adoption or feedback?",
"Are there concerns about competition in the smartphone market?"
]
# --- Function to Fetch Earnings Transcript ---
def get_earnings_transcript(ticker, year, quarter):
"""
Fetches the earnings call transcript content for a given company, year, and quarter.
Args:
ticker (str): The stock ticker symbol.
year (int): The fiscal year.
quarter (str): The quarter ('Q1', 'Q2', 'Q3', 'Q4').
Returns:
str or None: The transcript content as a single string if successful,
otherwise None. Returns metadata as a second value if needed.
"""
transcript_url = f"{BASE_URL}/earning_call_transcript/{ticker}?year={year}&quarter={quarter}&apikey={API_KEY}"
print(f"Attempting to fetch transcript from: {transcript_url}")
try:
response = requests.get(transcript_url, timeout=30) # Longer timeout for potentially large transcripts
response.raise_for_status()
data = response.json()
# FMP typically returns a list containing one dictionary
if isinstance(data, list) and len(data) > 0:
transcript_data = data[0]
if isinstance(transcript_data, dict) and 'content' in transcript_data:
print(f"Successfully fetched transcript for {ticker} {year} {quarter}.")
# Return content and optionally the full metadata dict
return transcript_data.get('content'), transcript_data
else:
print(f"Warning: Unexpected data structure in response list item: {transcript_data}")
return None, None
elif isinstance(data, list) and len(data) == 0:
print(f"Warning: Received empty list from API. No transcript found for {ticker} {year} {quarter}?")
return None, None
elif isinstance(data, dict) and 'Error Message' in data:
print(f"Error from API: {data['Error Message']}")
return None, None
else:
print(f"Warning: Received unexpected data format. Type: {type(data)}. Data: {str(data)[:200]}...")
return None, None
except requests.exceptions.RequestException as e:
print(f"Error fetching data: {e}")
return None, None
except requests.exceptions.JSONDecodeError as e:
print(f"Error decoding JSON response: {e}\nResponse text: {response.text}")
return None, None
except Exception as e:
print(f"An unexpected error occurred: {e}")
return None, None
# --- NEW: Helper Function to Extract Keywords from Question ---
# Very basic keyword extraction - removes common words and punctuation
COMMON_WORDS = set(["what", "is", "the", "are", "for", "how", "are", "a", "an", "of", "in", "on", "was", "were", "about", "or"])
def extract_keywords_from_question(question):
""" Extracts simple keywords from a question string. """
words = re.findall(r'\b\w+\b', question.lower()) # Find words
keywords = [word for word in words if word not in COMMON_WORDS and len(word) > 2] # Filter common/short words
return set(keywords) # Return unique keywords
# --- NEW: Helper Function to Split Text into Sentences ---
def split_into_sentences(text):
""" Splits text into sentences using basic punctuation. """
# Use regex to split by '.', '!', '?' followed by space or end of string. Handles basic cases.
sentences = re.split(r'(?<=[.!?])\s+', text)
return [s.strip() for s in sentences if s.strip()] # Remove empty strings and strip whitespace
# --- Main Execution Logic ---
if __name__ == "__main__":
print(f"\n--- Fetching Earnings Transcript for {TICKER} {YEAR} {QUARTER} ---")
transcript_content, transcript_metadata = get_earnings_transcript(TICKER, YEAR, QUARTER)
if transcript_content:
print("\n--- Transcript Sample (First 1000 Chars) ---")
print(transcript_content[:1000] + "...")
# --- Basic Keyword Analysis (Existing Functionality) ---
print("\n--- Performing Basic Keyword Frequency Analysis ---")
keyword_counts = {}
transcript_lower = transcript_content.lower() # Lowercase transcript once
for keyword in KEYWORDS_TO_SEARCH:
count = transcript_lower.count(keyword.lower())
keyword_counts[keyword] = count
# Only print if found to reduce noise
if count > 0:
print(f"Keyword '{keyword}': Found {count} times")
print("\n--- Keyword Counts Summary ---")
# Filter out zero counts for summary print
filtered_counts_summary = {k: v for k, v in keyword_counts.items() if v > 0}
print(filtered_counts_summary if filtered_counts_summary else "No specified keywords found.")
# --- Visualize Keyword Counts (Existing Functionality) ---
filtered_counts_plot = {k: v for k, v in keyword_counts.items() if v > 0}
if filtered_counts_plot:
print("\n--- Generating Keyword Frequency Plot ---")
keywords_plot = list(filtered_counts_plot.keys())
counts_plot = list(filtered_counts_plot.values())
plt.figure(figsize=(12, 7))
bars = plt.bar(keywords_plot, counts_plot)
plt.xlabel("Keywords")
plt.ylabel("Frequency Count")
plt.title(f"Keyword Frequency in {TICKER} {YEAR} {QUARTER} Earnings Transcript")
plt.xticks(rotation=45, ha='right')
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.bar_label(bars, padding=3)
plt.tight_layout()
plt.show()
else:
print("\nNo occurrences found for the specified keywords to plot.")
# --- Question Analysis Section ---
print("\n\n--- Performing Basic Question Analysis (Keyword Matching) ---")
print("Note: This finds sentences containing keywords from the question, not guaranteed answers.")
sentences = split_into_sentences(transcript_content)
print(f"Split transcript into {len(sentences)} potential sentences.")
# Minimum number of keywords from question that must be present in a sentence to be considered relevant
MIN_KEYWORD_MATCH_THRESHOLD = 2
for question in QUESTIONS_TO_ANALYZE:
print(f"\n❓ Question: {question}")
question_keywords = extract_keywords_from_question(question)
print(f" Keywords extracted: {question_keywords}")
relevant_sentences = []
if not question_keywords:
print(" Could not extract keywords from this question.")
continue
for sentence in sentences:
sentence_lower = sentence.lower()
# Count how many question keywords are in the sentence
match_count = 0
for keyword in question_keywords:
if keyword in sentence_lower:
match_count += 1
# Check if enough keywords match
if match_count >= min(MIN_KEYWORD_MATCH_THRESHOLD, len(question_keywords)) and match_count > 0: # Require at least threshold or all keywords if question is short
relevant_sentences.append(sentence)
if relevant_sentences:
print(f" Found {len(relevant_sentences)} potentially relevant sentences:")
for i, sent in enumerate(relevant_sentences):
# Limit display length for brevity
print(f" [{i+1}] ...{sent[:250]}..." if len(sent) > 250 else f" [{i+1}] {sent}")
if i >= 4: # Limit to showing first 5 matches per question
print(" (Showing first 5 matches...)")
break
else:
print(" No sentences found with significant keyword overlap.")
else:
print(f"\nCould not retrieve or process transcript for {TICKER} {YEAR} {QUARTER}.")
print("\n--- Script Finished ---")
Code Explanation: Step-by-Step
- Imports & Config: Imports
requests,pandas(optional),matplotlib.pyplot,os, andre(for text processing). Sets API key,BASE_URL, targetTICKER,YEAR, andQUARTER. Defines lists forKEYWORDS_TO_SEARCH(frequency) andQUESTIONS_TO_ANALYZE. SetsMIN_KEYWORD_MATCH_THRESHOLD. get_earnings_transcript(ticker, year, quarter)Function: Fetches the transcript using the/earnings-call-transcript/endpoint (note potential endpoint name change in FMP). Returns the transcript content string and metadata dictionary, with robust error handling and a longer timeout suitable for potentially large text data.- Helper Functions:
extract_keywords_from_question(question): Uses simple regex and a list of common words to pull potentially significant keywords from a question.split_into_sentences(text): Uses basic punctuation-based regex to split the transcript into a list of sentences. Note: This is imperfect and might split incorrectly on abbreviations or complex punctuation.
- Main Fetching Logic: Calls
get_earnings_transcript. If successful, prints a sample. - Basic Keyword Analysis (Frequency):
- Calculates the frequency of each word in
KEYWORDS_TO_SEARCHwithin the lowercase transcript. - Prints the counts for keywords found.
- Optionally generates a bar chart visualizing these frequencies.
- Calculates the frequency of each word in
- Question Analysis (Sentence Finding):
- Splits the transcript into sentences using the helper function.
- Iterates through each question in
QUESTIONS_TO_ANALYZE. - Extracts keywords from the question using the helper function.
- Iterates through each sentence of the transcript.
- Counts how many unique question keywords appear within the current sentence.
- If the count meets or exceeds the
MIN_KEYWORD_MATCH_THRESHOLD(or matches all keywords if the question yields fewer keywords than the threshold), the sentence is considered “potentially relevant”. - Prints the question, its extracted keywords, and the first few (up to 5) potentially relevant sentences found, or a message if none meet the threshold.
Interpreting the Results (Qualitative Context)
Let’s look at the output generated by our script for the hypothetical Apple 2025 Q1 earnings call transcript.
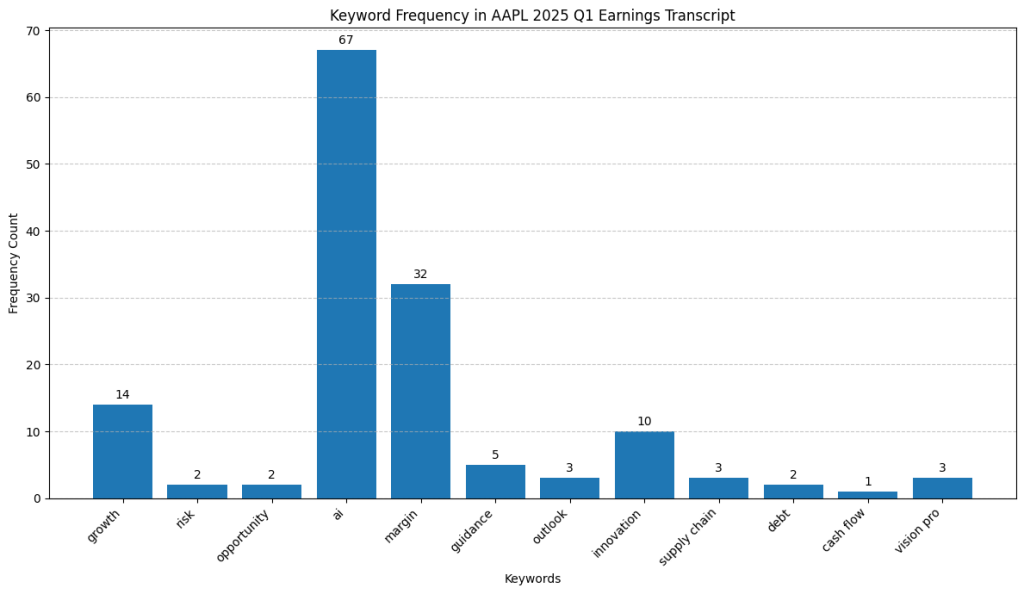
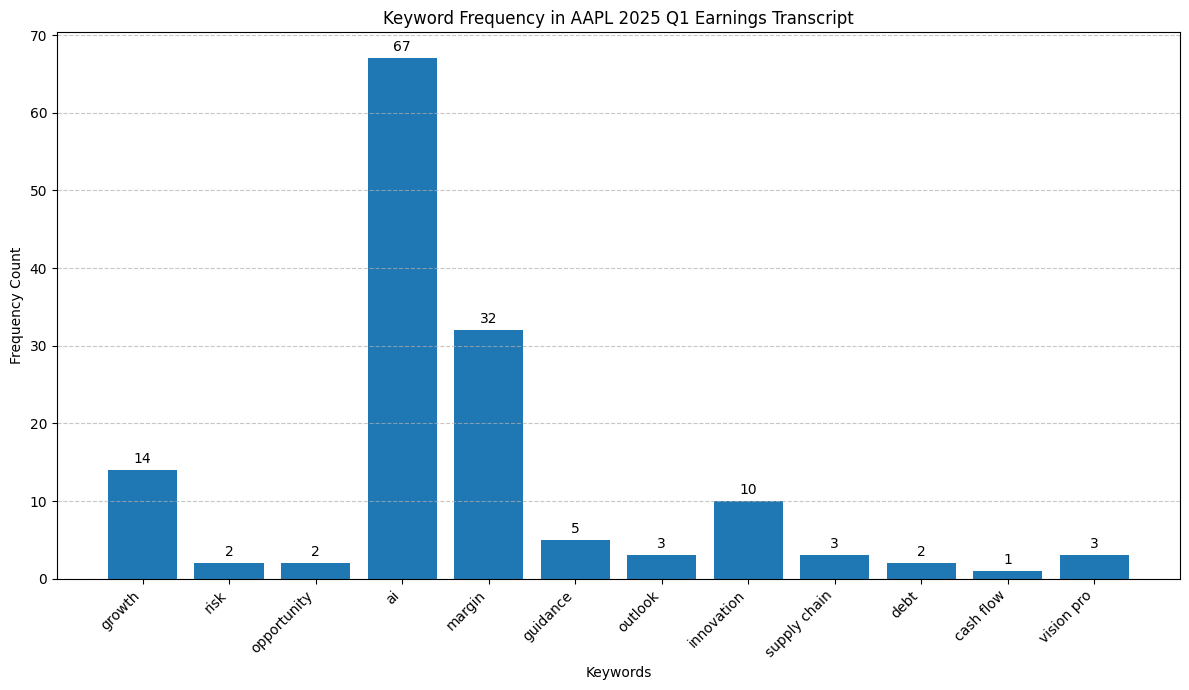
The bar chart quickly reveals the dominant themes based on the frequency of our chosen keywords:
- “ai”: This keyword appears most frequently by a large margin (67 times), strongly suggesting that Artificial Intelligence was a major topic of discussion during the call.
- “margin”: Mentioned frequently (32 times), indicating significant discussion around profitability margins (Gross, Operating, or Net).
- “growth” & “innovation”: These appear moderately often (14 and 10 times, respectively), signaling they were likely important secondary themes.
- Other Keywords: Terms like “guidance,” “outlook,” “supply chain,” and the specific product “vision pro” were mentioned but much less frequently. Keywords related to broader economic risks (“inflation”, “interest rate”), “debt,” or “cash flow” had very low or zero counts in this list, suggesting they were not primary focus points using these specific terms.
Takeaway from Frequency: The high counts immediately tell us to pay close attention to sections discussing AI and margins when reading the transcript. Growth and innovation are also key areas highlighted by frequency.
2. Question-Related Sentence Analysis:
The text output attempts to pinpoint sentences potentially relevant to our specific questions:

Combined Takeaway: The keyword frequency chart gave us the big picture (heavy focus on AI and margins). The sentence analysis helped zoom in on potential commentary related to specific questions about iPhone growth, Vision Pro, and market dynamics, saving time compared to reading all 489 sentences. However, it also showed limitations: it failed to find relevant sentences for the AI plans question despite AI being a major topic (due to keyword mismatch) and flagged some potentially irrelevant sentences for Vision Pro. These tools are best used together to guide, not replace, careful reading and interpretation of the full transcript context.
- CRUCIAL LIMITATIONS:
- Not True QA: This is keyword matching, not understanding. The script doesn’t comprehend the question or the sentence. A sentence might contain the keywords but discuss something unrelated or even contradict the implied query.
- Context Needed: You must read the surrounding sentences and paragraphs in the full transcript to understand the true meaning and context of the identified sentences.
- Basic NLP: Keyword extraction and sentence splitting are rudimentary. Synonyms are missed, complex sentences might be split incorrectly, and nuances of language are ignored.
- Threshold Tuning: The
MIN_KEYWORD_MATCH_THRESHOLDmight need adjustment depending on question complexity and desired sensitivity.
- Connecting Quantitative & Qualitative: This is where the power lies.
- Did profitability margins dip? Formulate a question like “What impacted margins?” and check the relevant sentences found by the script. Read management’s explanation.
- Did leverage increase? Ask “Why did debt increase?” or “What are capital allocation priorities?” and examine the identified commentary.
- Use the keyword counts and relevant sentences to find management’s narrative and outlook that contextualizes the ratios calculated in previous posts.
Conclusion: Adding Qualitative Flavor with Python
Qualitative insights from sources like earnings calls provide vital context for quantitative analysis. Python helps us efficiently retrieve and perform initial exploration of this text data.
We’ve moved from basic keyword frequency to a more targeted approach of finding sentences potentially related to specific questions using keyword matching. While still basic compared to advanced Natural Language Processing (NLP), this technique significantly speeds up the process of locating relevant information within long transcripts, acting as a valuable assistant for directing further manual reading and analysis. It effectively bridges the gap between your quantitative findings and the qualitative narrative provided by company management.
Next Steps: This opens the door to more advanced text analysis. In the next post, we will perform sentiment analysis on the latest Apple earning call.
Disclaimer: This blog post is for educational purposes only. Financial data APIs provide data “as is”; always verify critical data from official sources (e.g., SEC filings) before making investment decisions. Ensure compliance with API provider terms of service. This post was drafted with help of AI and reviewed and changed by the author.