9. Python for Fundamental Analysis: Gauge Market Tone with NLP Sentiment Analysis
Hello again, and welcome to the eighth installment of the Python for Finance series! We’ve journeyed from basic ratios to complex data retrieval and even dipped our toes into qualitative analysis by fetching earnings call transcripts and doing basic keyword searches. Catch up on the series here:
In Post 8, we saw that keyword counts lack nuance – they don’t capture the sentiment behind the words. Is management optimistic or cautious? Are analysts skeptical? This is where Natural Language Processing (NLP), specifically Sentiment Analysis, becomes valuable.
- Calculating P/E Ratio
- Automating Financial Statement Retrieval
- Calculating & Visualizing Profitability Ratios
- Analyzing Liquidity Ratios (Current & Quick)
- Analyzing Debt Ratios (Debt-to-Equity)
- Measuring Operational Efficiency (Turnover Ratios)
- Automate Peer Company Analysis & Benchmarking
- Unlock Insights with Earnings Call Transcript Analysis
Sentiment analysis computationally identifies the emotional tone (positive, negative, neutral) within text. In this post, we’ll use Python and the VADER library to perform sentiment analysis on earnings call transcripts, quantifying the underlying tone and visualizing the sentiment distribution.
Understanding Sentiment Analysis
What is Sentiment Analysis?
It’s the process of determining the emotional polarity (positive, negative, neutral) expressed in text.
Why Use it on Earnings Calls?
- Gauge Management Confidence: Assess tone regarding outlook, guidance, strategy.
- Identify Analyst Skepticism: Analyze sentiment in Q&A.
- Track Sentiment Shifts: Compare tone across quarters.
- Contextualize Quantitative Data: Align sentiment with financial results.
- Flag Sections for Review: Quickly find strongly positive/negative passages.
Introducing VADER
We’ll use VADER (Valence Aware Dictionary and sEntiment Reasoner). It’s a rule-based sentiment analysis tool effective for various texts, including financial ones. It’s efficient and easy to use. VADER provides positive, negative, neutral scores, and a combined compound score (-1 to +1) indicating overall polarity.
Python Implementation: Sentiment Analysis with VADER
Let’s fetch the transcript and apply VADER.
Installation & API Key: Install required libraries: pip install vaderSentiment requests pandas matplotlib. Remember to use your FMP API key (replace placeholder or use environment variables).
import requests
import pandas as pd
import matplotlib.pyplot as plt
import re # For sentence splitting
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer # Import VADER
import numpy as np
import os
# --- Configuration ---
# API Key provided by user (Normally, use environment variables for security)
API_KEY = "your_api_key"
# Base URL for FMP API version 3
BASE_URL = "https://financialmodelingprep.com/api/v3"
# --- Parameters for Transcript ---
TICKER = "AAPL"
YEAR = 2025
QUARTER = "Q1" # Options: Q1, Q2, Q3, Q4
# --- Function to Fetch Earnings Transcript ---
# Reusing the function from previous posts
def get_earnings_transcript(ticker, year, quarter):
""" Fetches the earnings call transcript content. """
transcript_url = f"{BASE_URL}/earning_call_transcript/{ticker}?year={year}&quarter={quarter}&apikey={API_KEY}"
print(f"Attempting to fetch transcript from: {transcript_url}")
try:
response = requests.get(transcript_url, timeout=30)
response.raise_for_status()
data = response.json()
if isinstance(data, list) and len(data) > 0:
transcript_data = data[0]
if isinstance(transcript_data, dict) and 'content' in transcript_data:
print(f"Successfully fetched transcript for {ticker} {year} {quarter}.")
return transcript_data.get('content'), transcript_data
else:
print(f"Warning: Unexpected data structure in response list item: {transcript_data}")
return None, None
elif isinstance(data, list) and len(data) == 0:
print(f"Warning: Received empty list from API. No transcript found for {ticker} {year} {quarter}?")
return None, None
elif isinstance(data, dict) and 'Error Message' in data:
print(f"Error from API: {data['Error Message']}")
return None, None
else:
print(f"Warning: Received unexpected data format. Type: {type(data)}. Data: {str(data)[:200]}...")
return None, None
except requests.exceptions.RequestException as e:
print(f"Error fetching data: {e}")
return None, None
except requests.exceptions.JSONDecodeError as e:
print(f"Error decoding JSON response: {e}\nResponse text: {response.text}")
return None, None
except Exception as e:
print(f"An unexpected error occurred: {e}")
return None, None
# --- Helper Function to Split Text into Sentences ---
# Reusing the function from previous code edit
def split_into_sentences(text):
""" Splits text into sentences using basic punctuation. """
sentences = re.split(r'(?<=[.!?])\s+', text)
# Further clean up potential empty strings or artifacts from splitting
return [s.strip() for s in sentences if s and s.strip() and len(s.strip()) > 5] # Added length check
# --- Main Execution Logic ---
if __name__ == "__main__":
print(f"\n--- Fetching Earnings Transcript for {TICKER} {YEAR} {QUARTER} ---")
transcript_content, transcript_metadata = get_earnings_transcript(TICKER, YEAR, QUARTER)
if transcript_content:
print("\n--- Performing Sentiment Analysis using VADER ---")
# Initialize VADER Analyzer
analyzer = SentimentIntensityAnalyzer()
# Split transcript into sentences
sentences = split_into_sentences(transcript_content)
print(f"Split transcript into {len(sentences)} sentences.")
if not sentences:
print("Could not split transcript into sentences. Exiting analysis.")
else:
# Analyze sentiment for each sentence
sentiment_results = []
print("Analyzing sentiment per sentence...")
for sentence in sentences:
vs = analyzer.polarity_scores(sentence)
sentiment_results.append({
'sentence': sentence,
'compound': vs['compound'],
'positive': vs['pos'],
'negative': vs['neg'],
'neutral': vs['neu']
})
# Create DataFrame from results
df_sentiment = pd.DataFrame(sentiment_results)
print(f"Created DataFrame with {len(df_sentiment)} sentence sentiments.")
if not df_sentiment.empty:
# --- Overall Sentiment ---
average_compound = df_sentiment['compound'].mean()
print(f"\n--- Overall Sentiment ---")
print(f"Average Compound Score: {average_compound:.4f}")
if average_compound > 0.05:
print("Overall Tone: Generally Positive")
elif average_compound < -0.05:
print("Overall Tone: Generally Negative")
else:
print("Overall Tone: Generally Neutral")
# --- Visualize Sentiment Distribution ---
print("\n--- Generating Sentiment Score Distribution Plot ---")
plt.figure(figsize=(10, 6))
plt.hist(df_sentiment['compound'], bins=30, color='skyblue', edgecolor='black')
plt.title(f'Distribution of Sentence Sentiment Scores ({TICKER} {YEAR} {QUARTER})')
plt.xlabel('Compound Sentiment Score (-1 to +1)')
plt.ylabel('Number of Sentences')
plt.axvline(0, color='grey', linestyle='dashed', linewidth=1) # Add line at neutral 0
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
# --- Extract Most Positive/Negative Sentences ---
print("\n--- Example Sentences ---")
df_sorted = df_sentiment.sort_values(by='compound', ascending=False)
print("\nTop 5 Most Positive Sentences:")
for index, row in df_sorted.head(5).iterrows():
print(f" Score: {row['compound']:.3f} | Sentence: ...{row['sentence'][:200]}...") # Truncate long sentences
print("\nTop 5 Most Negative Sentences:")
for index, row in df_sorted.tail(5).iloc[::-1].iterrows(): # Use tail().iloc[::-1] to show most negative first
print(f" Score: {row['compound']:.3f} | Sentence: ...{row['sentence'][:200]}...") # Truncate long sentences
else:
print("Sentiment DataFrame is empty after analysis.")
else:
print(f"\nCould not retrieve transcript for {TICKER} {YEAR} {QUARTER}. Cannot perform sentiment analysis.")
print("\n--- Script Finished ---")Code Explanation: Step-by-Step
- Import Libraries: Imports
requests,pandas,matplotlib.pyplot,re,os, and cruciallySentimentIntensityAnalyzerfromvaderSentiment.vaderSentiment. - Configuration: Sets API key, ticker, year, quarter, etc.
get_earnings_transcriptFunction: Reuses the function to fetch the transcript content string and metadata.split_into_sentencesFunction: Reuses the regex-based sentence splitter, adding a minimum length check (len > 5) to filter out very short, potentially meaningless fragments.- Main Logic (Sentiment Analysis):
- Fetches the transcript content.
- Initializes VADER: Creates an instance
analyzer = SentimentIntensityAnalyzer(). - Splits into Sentences: Calls
split_into_sentences. - Analyzes Sentence Sentiment: Loops through the
sentenceslist. For each sentence,analyzer.polarity_scores(sentence)is called. This returns a dictionary like{'neg': 0.0, 'neu': 0.7, 'pos': 0.3, 'compound': 0.4588}. These scores (especially the overallcompoundscore) are stored along with the sentence. - Creates DataFrame: The list of results is converted into a
pandasDataFramedf_sentimentfor easier manipulation. - Calculates Overall Average: Computes the mean of the ‘compound’ scores across all sentences and provides a simple interpretation (Positive/Neutral/Negative based on thresholds like +/- 0.05).
- Visualizes Distribution: Creates a histogram (
plt.hist) showing how many sentences fall into different ‘compound’ score ranges (bins). A vertical line at zero helps distinguish positive from negative. - Extracts Example Sentences: Sorts the DataFrame by the ‘compound’ score. It then prints the text of the top 5 sentences with the highest scores (most positive) and the top 5 with the lowest scores (most negative), showing their scores for context.
- Error Handling: Includes checks for failed API calls, inability to split sentences, and empty DataFrames.
Interpreting the Sentiment Results
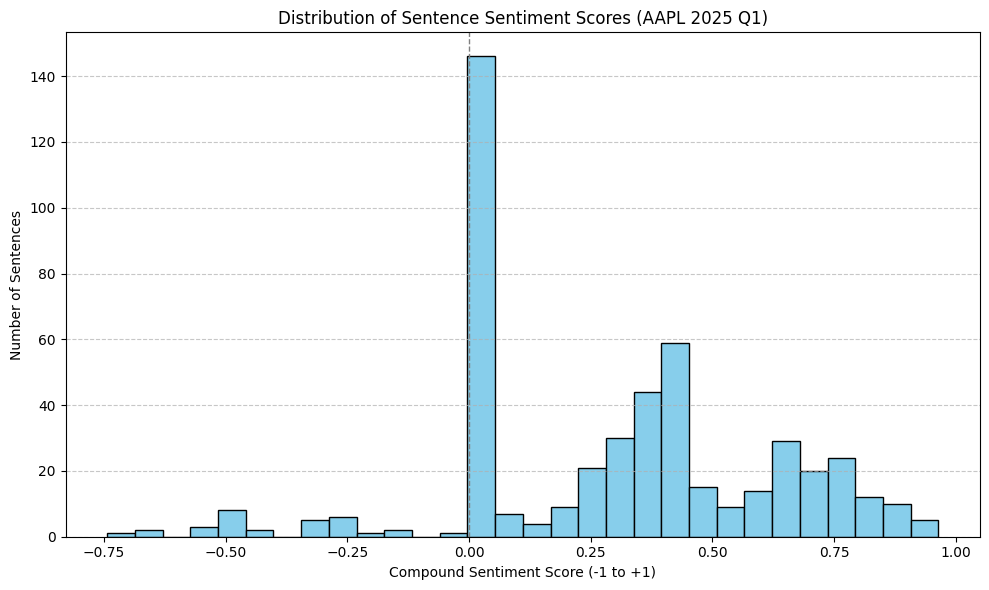
- Overall Shape: The histogram displays the distribution of compound sentiment scores for sentences in the transcript. We can clearly see the distribution is skewed towards the positive side (scores > 0).
- Neutral Peak: There is a very large peak around the neutral score (compound score close to 0), indicating a significant portion of the transcript consists of factual statements or neutral language.
- Positive Skew: There’s a substantial number of sentences falling into positive territory (scores roughly between 0.1 and 0.9), suggesting considerable use of optimistic or positive language.
- Negative Tail: While there are some sentences with negative scores (scores < 0), they are much less frequent than the positive ones, and most fall in the moderately negative range (e.g., -0.75 to -0.25).
- Implied Average: This distribution suggests the average compound score (calculated earlier by the script) would likely be slightly positive, reflecting the higher frequency and magnitude of positive sentences compared to negative ones, despite the large neutral base.
Takeaway from Histogram: The overall tone of the earnings call appears to be neutral-to-positive, dominated by factual statements but with a significant amount of positive language used throughout. Strongly negative language seems relatively limited.
2. Example Sentences:
Top 5 Most Positive Sentences:
Score: 0.964 | Sentence: …But taking the current high levels of profitability as fairly stable, what observations might you share about price sensitivity of users and whether having a wider range of pricing across the products… [Analyst Question?]
Score: 0.956 | Sentence: …Thanks to our incredible customer satisfaction and strong loyalty, our installed base of active devices reached an all-time high across all products and geographic segments and is now over 2.35 billio…
Score: 0.936 | Sentence: …Services continues to see strong momentum, and the growth of our installed base of active devices gives us great opportunities for the future….
Score: 0.929 | Sentence: …They can use writing tools to help find just the right words, create fun and unique images with Image Playground and Genmoji, handle daily tasks and seek out information with a more natural and conver…
Score: 0.924 | Sentence: …With its most advanced display yet and a thinner more comfortable design, the all-new Apple Watch Series 10 is the perfect companion to help users pursue their health and fitness goals this year….
Top 5 Most Negative Sentences:
Score: -0.743 | Sentence: …I recently got a note from a customer who put his watch on his father’s wrist when he feared something was wrong with him…. [Anecdote – negative words, positive product implication?]
Score: -0.649 | Sentence: …Tim Cook: I think the killer feature is different for different people…. [Ambiguous – ‘killer’ might trigger negativity]
Score: -0.648 | Sentence: …We repaid $1 billion in maturing debt and decreased commercial paper by $8 billion, resulting in $97 billion in total debt…. [Factual – ‘debt’, ‘decreased’ trigger negativity]
Score: -0.572 | Sentence: …We expect OI&E to be around negative $300 million, excluding any potential impact from the mark-to-market of minority investments, and our tax rate to be around 16%…. [Factual forecast with ‘negative’]
Score: -0.542 | Sentence: …These statements involve risks and uncertainties that may cause actual results or trends to differ materially from our forecast…. [Standard disclaimer – ‘risks’, ‘uncertainties
Negative Themes & VADER Limitations: The most negative sentences highlight VADER’s limitations:
- Sentence [1] uses negative words (“feared,” “wrong”) within an anecdote that might actually imply a positive use case for the Apple Watch.
- Sentence [3] describes debt repayment, typically viewed positively for financial health, but the words “debt” and “decreased” likely trigger VADER’s negative score.
- Sentence [4] is a factual statement about a financial item expected to be negative.
- Sentence [5] is standard legal disclaimer language about risks, which appears in almost all earnings calls.
- Sentence [2] is ambiguous; “killer feature” might be interpreted negatively by the lexicon.
- Crucially, none of these top negative sentences seem to reflect deep pessimism about Apple’s core performance or outlook in themselves, though they point to standard business discussions (debt, risk factors, specific financial line items).
Conclusion: Quantifying the Qualitative Tone
Sentiment analysis using NLP tools like VADER adds a valuable dimension to our analysis of earnings call transcripts. It allows us to move beyond simple keyword presence and attempt to quantify the underlying tone and attitude. By analyzing sentiment at the sentence level and visualizing the distribution, we can quickly identify the prevailing mood and pinpoint specific statements of strong optimism or concern.
While not a perfect replacement for human understanding, NLP sentiment analysis provides a powerful way to process large amounts of text efficiently, flag areas for deeper review, and integrate qualitative insights more systematically into our Python-driven fundamental analysis workflow.
Stay tuned as we continue to expand our Python for Finance toolkit! In the next post, we will see how to calculate Free Cash Flow using Python.
Disclaimer: This blog post is for educational purposes only. Financial data APIs provide data “as is”; always verify critical data from official sources (e.g., SEC filings) before making investment decisions. Ensure compliance with API provider terms of service. This post was drafted with help of AI and reviewed and changed by the author.