3. Python Growth Stock Screener
Welcome back to our Python for Finance series! Having explored value stocks and dividend payers, we now turn our attention to another exciting category: growth stocks. This post will show you how to build a Python growth stock screener to identify companies exhibiting strong expansion potential using yfinance and pandas.
What is a Growth Stock?
Growth investing focuses on companies expected to grow their revenue and earnings at an above-average rate compared to their industry or the overall market. Investors buy these stocks anticipating that their rapid expansion will lead to significant capital appreciation (stock price increase), often prioritizing growth potential over current profitability or dividend payouts.
Key characteristics often associated with growth stocks include:
- Strong Revenue Growth: The company is consistently increasing its sales.
- Rising Earnings Per Share (EPS): Profits attributable to each share are growing, indicating increasing profitability or efficiency.
- Innovation & Market Leadership: Often found in expanding industries or possessing competitive advantages that fuel growth.
Our goal is to use Python to filter stocks based on quantitative growth metrics.
Our Growth Screener Logic: Revenue and Earnings Momentum
For this screener, we’ll target companies showing recent strong performance in both top-line (revenue) and bottom-line (earnings) growth. We’ll use the following criteria, based on data potentially available in the yfinance info dictionary:
- Revenue Growth (> 10%): We’ll look for companies whose revenue has recently grown by more than 10%. The
yfinancelibrary provides arevenueGrowthkey. - Earnings Growth (> 10%): Similarly, we’ll screen for companies whose earnings have grown by more than 10%.
yfinanceoffer anearningsGrowthkey (again, often quarterly year-over-year).
Important Note on Data: The specific growth metrics like revenueGrowth and earningsGrowth within yfinance‘s info dictionary can sometimes be inconsistent, unavailable for certain stocks, or represent different time periods (e.g., trailing twelve months vs. most recent quarter). This screener relies on their availability.
Our aim is to find companies demonstrating recent, significant expansion in both sales and profits, suggesting strong business momentum.
Python Implementation: Code for Screening Growth Stocks
# Import necessary libraries
import pandas as pd
import yfinance as yf
import warnings
# Ignore specific warnings from yfinance if necessary (optional)
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", message="Passing literal json to 'read_json' is deprecated")
def screen_growth_stocks(tickers):
"""
Screens a list of stock tickers for growth criteria based on revenue
and earnings growth potentially available in yfinance info.
Args:
tickers (list): A list of stock ticker symbols (strings).
Returns:
pandas.DataFrame: A DataFrame containing stocks that meet the growth criteria,
including Ticker, Company Name, Revenue Growth, and Earnings Growth.
Returns an empty DataFrame if no stocks pass or data is missing.
"""
filtered_stocks = [] # List to hold stocks that pass the filters
print(f"Screening {len(tickers)} tickers for growth criteria...")
# --- Define Screening Criteria ---
# Minimum growth rate for both revenue and earnings
min_growth_rate = 0.10 # e.g., 10% growth
# ---------------------------------
# Loop through each ticker symbol
for ticker in tickers:
try:
# Create a Ticker object
stock = yf.Ticker(ticker)
# Fetch stock information
info = stock.info
# Safely get growth metrics using .get()
# Returns None if the key doesn't exist
# Note: Availability and definition of these keys in yfinance can vary!
revenue_growth = info.get('revenueGrowth')
earnings_growth = info.get('earningsGrowth')
company_name = info.get('shortName', 'N/A')
# --- Apply the filtering logic ---
# Check if data exists AND meets the criteria
if (revenue_growth is not None and earnings_growth is not None and
revenue_growth > min_growth_rate and
earnings_growth > min_growth_rate):
# If criteria are met, add stock details to our list
filtered_stocks.append({
'Ticker': ticker,
'Company Name': company_name,
# Format growth rates as percentages
'Revenue Growth': f"{revenue_growth * 100:.2f}%",
'Earnings Growth': f"{earnings_growth * 100:.2f}%"
})
print(f" [PASS] {ticker} (Revenue Growth: {revenue_growth*100:.2f}%, Earnings Growth: {earnings_growth*100:.2f}%)")
else:
# Provide reason for failure if possible
reason = []
if revenue_growth is None: reason.append("No revenue growth data")
elif revenue_growth <= min_growth_rate: reason.append(f"Revenue growth {revenue_growth*100:.2f}% <= {min_growth_rate*100:.1f}%")
if earnings_growth is None: reason.append("No earnings growth data")
elif earnings_growth <= min_growth_rate: reason.append(f"Earnings growth {earnings_growth*100:.2f}% <= {min_growth_rate*100:.1f}%")
print(f" [FAIL] {ticker} - {' | '.join(reason) if reason else 'Criteria not met or data missing.'}")
except Exception as e:
# Handle potential errors during data fetching for a specific ticker
print(f" [ERROR] Could not process {ticker}: {e}")
continue # Skip to the next ticker
print("\nScreening complete.")
# Convert the list of dictionaries to a pandas DataFrame
if filtered_stocks:
results_df = pd.DataFrame(filtered_stocks)
# Reorder columns
results_df = results_df[['Ticker', 'Company Name', 'Revenue Growth', 'Earnings Growth']]
else:
results_df = pd.DataFrame(columns=['Ticker', 'Company Name', 'Revenue Growth', 'Earnings Growth'])
return results_df
# --- Main Execution ---
if __name__ == "__main__":
# Define the list of stock tickers to screen
# Using a similar list, including some known growth names and others
ticker_list = [
'AAPL', 'MSFT', 'GOOGL', 'AMZN', 'META', 'NVDA', # Tech / Growth
'TSLA', # EV / Growth
'JPM', 'BAC', # Banks (lower growth usually)
'PFE', 'JNJ', 'LLY', # Pharma (mixed growth)
'XOM', 'CVX', # Energy (cyclical growth)
'WMT', 'COST', # Retail (moderate growth)
'INTC', 'AMD', # Semiconductors (can be high growth)
'F', 'GM', # Auto (cyclical)
'DIS', 'NFLX', # Entertainment (growth varies)
'KO', 'PEP', # Consumer staples (lower growth usually)
'RDDT' # Example fail case
]
# Run the screener function
growth_stocks_df = screen_growth_stocks(ticker_list)
# Display the results
print("\n--- Growth Stock Screener Results ---")
if not growth_stocks_df.empty:
print(growth_stocks_df.to_string(index=False))
else:
print(f"No stocks met the specified growth criteria (Revenue & Earnings Growth > {min_growth_rate*100:.1f}%) based on available yfinance data.")
print("\nDisclaimer: This information is for educational purposes only and not financial advice.")Let’s write the Python script to identify stocks with high revenue and earnings growth. Make sure pandas and yfinance are installed (pip install pandas yfinance).
- Imports & Setup: Import
pandas,yfinance, and manage warnings.
screen_growth_stocksFunction: Defines the main logic for our growth screener.
- Tickers & Storage: We define our
tickerslist and initializefiltered_stocks.
- Looping & Fetching: Iterate through tickers, create
yf.Tickerobjects, and fetch theinfodictionary.
- Accessing Growth Metrics Safely: We use
info.get('revenueGrowth')andinfo.get('earningsGrowth')to retrieve the values. Using.get()preventsKeyErrorif these specific keys are missing for a stock, returningNoneinstead. We store the company name usinginfo.get('shortName', 'N/A').
- Applying Growth Filters: We define our minimum growth thresholds (
min_growth_rate = 0.10for 10%). The coreifcondition checks:- That both
revenue_growthandearnings_growthare notNone(data is available). - That
revenue_growthis greater thanmin_growth_rate. - That
earnings_growthis greater thanmin_growth_rate.
- That both
- Storing Results: If a stock passes, its Ticker, Name, Revenue Growth, and Earnings Growth are added to the
filtered_stockslist, formatted as percentages.
- DataFrame Creation & Output: The list is converted to a
pandasDataFrame, and the results (or a message if none pass) are printed.
Python output High Growth Screener
Below is the output I get when running the code:
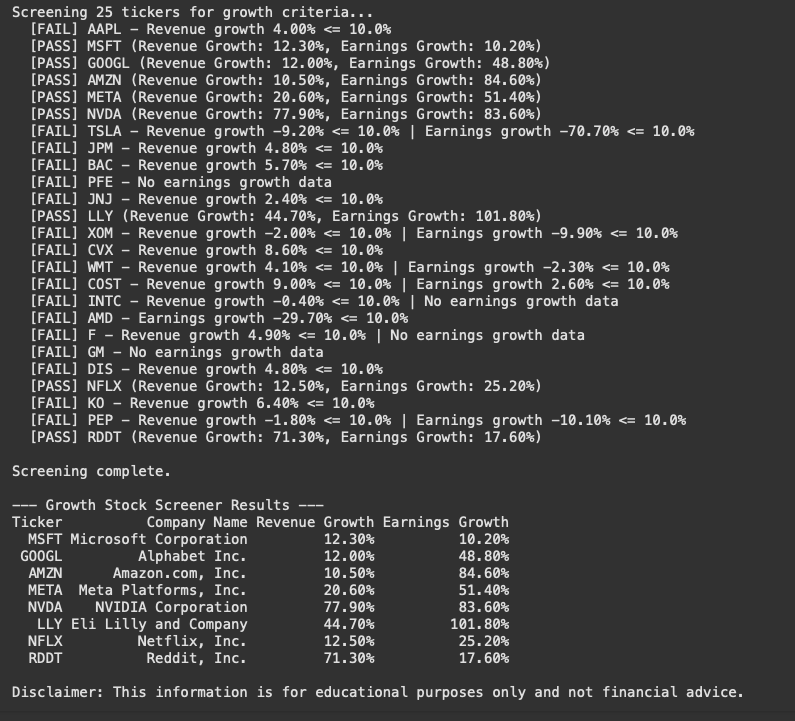
Companies like Microsoft, Alphabet (Google), Amazon, Meta, NVIDIA, Eli Lilly, Netflix, and Reddit all showed recent revenue and earnings growth rates exceeding the 10% threshold set in the Python script. They passed the growth screen.
Remember, this is based on potentially backward-looking data available at a specific moment and doesn’t guarantee future performance or consider valuation.
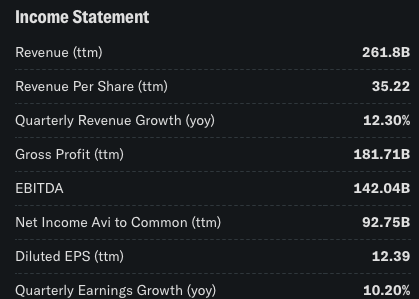
Also, always do a spot check when running Python code to ensure that you are retrieving the right data. For example, in Yahoo finance, in the statistics section, we can see the same Revenue and earnings growth as the code returned:
Limitations and Next Steps
This growth screener is a useful tool but has limitations:
- Data Dependency: Its effectiveness hinges on the availability and definition of the
revenueGrowthandearningsGrowthfields inyfinance. These might not always be present or comparable across all stocks. - Backward-Looking: Like our previous screeners, it relies on past performance, which doesn’t guarantee future results. High growth can be difficult to sustain.
- Valuation Ignored: This screener doesn’t consider price. A high-growth stock might already be very expensive (high P/E ratio).
- No Qualitative Factors: It doesn’t account for management quality, competitive landscape, or industry trends.
Further research is essential. Investigate why the company is growing and whether that growth is sustainable and reasonably priced.
In our final post, we’ll explore combining screening factors (like value and growth for a GARP approach) and potentially adding simple technical indicators to refine our Python stock screeners.
Disclaimer: This educational content is not financial advice. Stock screening is only one part of investment analysis. Always conduct thorough due diligence or consult a qualified financial advisor before investing. This blog post was drafted with the assistance of AI tools and reviewed and edited by the author.